


– by Tinus le Roux (founder)
At CrowdIQ we don’t use facial recognition (see here)
We do however use computer vision to do anonymous crowd analysis.
The differences are more than semantics, but to understand why a quick introduction to computer vision will help…
Part 1: An Introduction to Computer Vision
Computer vision is a highly technical field in Artificial Intelligence, but practically it comes down to this: Everything a human can deduce from an image, a computer can be trained to deduce from an image.
One of the big differences between humans and computers in this regard is that while facial analysis and recognition are seamlessly ‘integrated’ into our brains, these are very distinct and separate functions in the world of computing.
Let’s use the picture below to walk through the different computer functions – and their human equivalents – involved:

1. Face Detection: The ability to identify an object as a face.
It is face detection that allows you to look at the picture above and conclude that there are 231 people in it.
Wait, there aren’t 231 faces in this picture? How do you know?
Well, that’s your ‘internal face detection algorithm’ at work. Humans are very good at detecting faces – and consequently, so are computers.
2. Face Analysis : The ability to estimate the age, gender, race and mood of a detected face.
You’re able to estimate the genders and ages of the people in our picture NOT because you know the precise facial geometry for males and females, but because you’re really good at comparing faces to your ‘training data’. You’ve seen enough females and males by now that it’s relatively easy for your brain to compare each of the faces on the stage to ‘what you know’ and estimate a gender for each.
Age is a bit more difficult, but that’s only because some 40-year-olds look like they’re 30 and others look like they’re 50 and therefore your ‘training data’ is less ‘accurate’.
The point is: in much the same way that a quarterback doesn’t need to be a math genius to estimate the power and angle of a throw, we don’t need to be geometry experts to estimate gender and age. It’s a comparative study of some sorts. Comparing your scenario data (how hard to throw or if to say ‘excuse me Ma’am’ or ‘excuse me Sir’) with previous scenarios and estimating where it fits in on a continuum.
Computers work in much the same way.
When analyzing a face, it will give you a male/female estimate as well as a percentage of certainty to go with it. When it comes to age it will provide a range. To see how it works in practice, I ran this image through Amazon’s Rekognition program and included the results below:
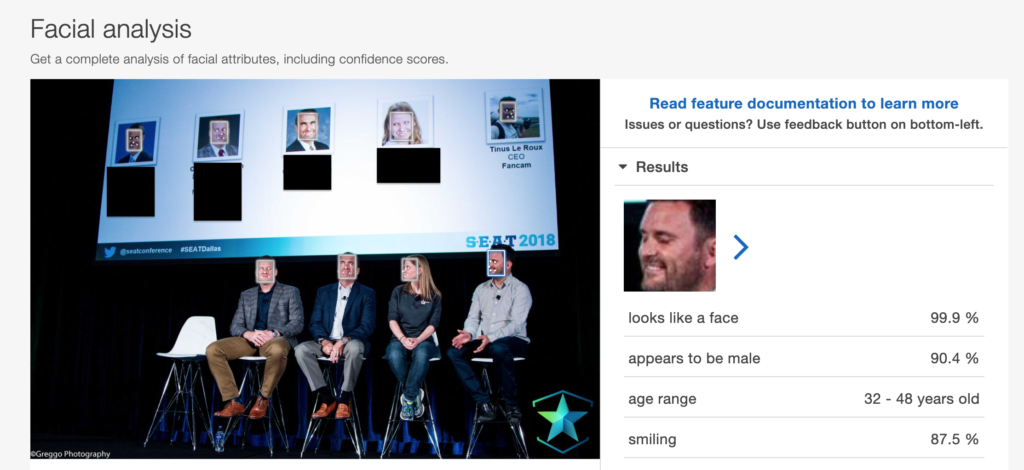
As you can see from the image, Rekognition picked up 8 faces (profile pics included) and I then asked it to analyze mine.
Note the percentage certainty for each category and the ranges used for age.
3 Face Matching: Comparing two faces and returning a similarity score.
Let’s use the gentleman on the left as an example.
Is his profile picture up on the big screen?
To answer this question your brain subconsciously compared his face to ALL of the profile pictures visible and found that one had a very high level of similarity.
In the case of an algorithm, the results will come back as ‘percentage similar’ and you’ll tell your program to accept ‘80% similarity’ as a ‘match’.
4. Face Recognition: Assigning identity to a face.
Right, we’re still with the gentleman on the left.
Next question: what’s his name, surname, title and email address?
It’s a trick question, but it’s at the heart of understanding the power and limitations of facial recognition.
Here’s the point: I’m able to answer this question almost as quickly and easily as you answered the gender question earlier, but only because I know him.
Without knowing someone, it’s impossible to recognize them.
In the same way that you can’t look at a person and say “That looks like a Tom”, a computer can’t look at a face and guess the identity of the owner.
The key is in the word: RE-cognition.

Both humans and computers require prior knowledge of identity in order to do facial recognition.
Without prior knowledge, we can do detection, analysis and even matching, but we cannot RE-cognize someone without already knowing them.
Part 2: How we use Computer Vision
So now that we have a bit more insight into how Computer Vision actually works, let’s revisit my original statement…
We don’t use Facial Recognition.
We don’t own (or have access to) a database of identities.
Our system doesn’t know people and it is therefore impossible for it to ‘re-know’ anyone.
Apart from the fact that we’re not able to do it and that we think it’s ethically dubious, we’re honestly just not that interested in it either.
We just think that it’s much more interesting to try and understand crowds as ‘organisms’.
How they react differently depending on their composition.
Whether that behavior is predictable and can be used to create a better experience for fans and more efficient business for sports teams.
Take the use case of Crowd Flow as an example.
This is where we use Face Detection to count how many fans are seated at a particular point in time.
Sports teams know when people enter their buildings because tickets are scanned at the turnstiles, but it’s very difficult for them to figure out when people leave the stadium. Our data allows them to understand exactly when people are starting to leave their seats and when we overlay data like the score and weather conditions, we’re able to start predicting when and how fast fans will be leaving.
This is important because it means the team can start adjusting their staffing in real-time and run a more efficient business.
In this use case (as with all our use cases), we never touched identity.
Facial recognition was never used and the identities of those counted were never known.
It’s not that we anonymized the data, it’s that the data is completely and utterly anonymous.
To summarize …
- We do detect faces in a crowd – in order to count them (Crowd Flow).
- We do use facial analysis – to determine the average age and the gender distribution in crowds (Demographics).
- We do use face matching to count the percentage of fans returning from one game to another (Frequency),
- but we don’t use facial recognition.
Part 3: “but what if….”
While I feel the technical explanation above addresses the issue sufficiently, I want to go one step further and answer a question I have to ask myself:
“This is all good and well, but what’s stopping you (or someone else) from weaponizing your tech in the future?”
It’s an important question, as the tech industry has a well-documented history of endeavors that started with good intentions but ended up causing great harm.
The short answer is ‘enlightened self-interest’, but allow me to break it down:
- Ethics
- I certainly don’t go to public events so that anonymous camera companies can track and trace me without my permission. My wife certainly didn’t upload her Facebook profile picture so that people can scrape it and use it to track her. As my grandmother often said “No good can come of it” and while it may sound commercially naive, I just don’t think it’s smart business pursuing an avenue with such high potential for misuse and overreach.
- Law
- Even with US Federal law lagging behind on this topic, states like Illinois and California have made it clear that using Facial Recognition without explicit consent is illegal – and my hope is that this will spread to other states too.
- Startup reality
- It’s important to understand the difference between a startup (where the founder/CEO also writes the blog posts) and companies like Facebook and Google. Mark Zuckerberg can afford to take chances on things like the legality and ethics of Facial Recognition. If something goes wrong, he sends lobbyists or lawyers to sort it out and if they don’t, they pay a fine. Startups like CrowdIQ simply cannot afford to be wrong or even be perceived to be wrong on topics like this. Our investors will lose their money, my team will lose their jobs and I won’t work in this industry again.
- Commercial
- Honestly, even if we could get over the ethics and legal hurdles I really don’t see the commercial value.
One last point on the difference between potential harm and actual harm that people often miss when it comes to new technologies: Technology does not operate in isolation – and thank goodness for that. In evaluating new tech, it’s important to think of it in the context of the legal system and particular society in which it will be deployed.
Let’s take cars as an example.
We don’t think that owning a car is criminal or unethical just because it has the potential to cause a road accident or be used to drive into a crowd of protestors.
We do however do everything in our power to make these outcomes as unlikely as possible by:
- Insisting on a minimum age for drivers
- Requiring a driver’s license
- Enforcing safety standards
- Making seat belts mandatory
- Prohibiting driving under the influence
- Making sure there’s a legal system in place to deal with transgressors
In short: owning a car isn’t illegal, but when you ask a driver “what prevents you from using this potential weapon to harm others?”, their answer may well be a combination of “it’s wrong, there’s no motivation for me to do this”, and “I don’t want to go to jail.”
The same is true of people like us who work with the ‘tools of the trade’ (pictures).
It’s also important to recognize that there is a big difference between the potential to do harm and doing actual harm and that there are legal consequences incentivizing us not to do the latter.
That all being said, the responsibility to be transparent will always be ours and I hope this post serves as a reflection of how seriously we take that responsibility.